Stories



-
![العملية العسكرية الروسية في أوكرانيا]()
العملية العسكرية الروسية في أوكرانيا
RT STORIES
روسيا.. مقتل 4 أشخاص بينهم طفل باعتداءات أوكرانية بالمسيرات
![روسيا.. مقتل 4 أشخاص بينهم طفل باعتداءات أوكرانية بالمسيرات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
تدمير مسيرتين متجهتين إلى موسكو وحريق في مستودع نفط بعد سقوط مسيرة في جنوب روسيا
![تدمير مسيرتين متجهتين إلى موسكو وحريق في مستودع نفط بعد سقوط مسيرة في جنوب روسيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مدفيديف: الغرب لا يريد حربا نووية ونخبه تتمنى هزيمة روسيا وتفككها
![مدفيديف: الغرب لا يريد حربا نووية ونخبه تتمنى هزيمة روسيا وتفككها]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بعثة روسيا لدى الأمم المتحدة: عواصم أوروبية متواطئة في صنع مسيرات تستخدمها كييف لقتل الأطفال الروس
![بعثة روسيا لدى الأمم المتحدة: عواصم أوروبية متواطئة في صنع مسيرات تستخدمها كييف لقتل الأطفال الروس]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"الخماسية الأوروبية" تسعى لتعميق الشراكة بين الناتو وأوكرانيا وتقريبها من الحلف
!["الخماسية الأوروبية" تسعى لتعميق الشراكة بين الناتو وأوكرانيا وتقريبها من الحلف]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
القوات الروسية تخترق الدفاعات الأوكرانية وتتقدم بعمق 15 كيلومترا داخل مقاطعة سومي الحدودية
![القوات الروسية تخترق الدفاعات الأوكرانية وتتقدم بعمق 15 كيلومترا داخل مقاطعة سومي الحدودية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![العملية العسكرية الروسية في أوكرانيا]() العملية العسكرية الروسية في أوكرانيا
العملية العسكرية الروسية في أوكرانيا
-
![مونديال 2026]()
مونديال 2026
RT STORIES
تكلفة جديدة في المونديال.. حتى الطريق إلى الملعب ليس مجانيا!
![تكلفة جديدة في المونديال.. حتى الطريق إلى الملعب ليس مجانيا!]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
سيناريوهات التأهل.. الفراعنة يضعون قدما في دور الـ32 قبل موقعة إيران الحاسمة
![سيناريوهات التأهل.. الفراعنة يضعون قدما في دور الـ32 قبل موقعة إيران الحاسمة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
تاريخ يُكتب.. البوسنة أول المتأهلين كأفضل ثالث إلى دور الـ32
![تاريخ يُكتب.. البوسنة أول المتأهلين كأفضل ثالث إلى دور الـ32]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
جنوب إفريقيا تصنع المفاجأة وتخطف بطاقة التأهل من كوريا الجنوبية في مونديال 2026
![جنوب إفريقيا تصنع المفاجأة وتخطف بطاقة التأهل من كوريا الجنوبية في مونديال 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
المكسيك تحقق العلامة الكاملة بدور المجموعات لأول مرة.. والتشيك تودع المونديال
![المكسيك تحقق العلامة الكاملة بدور المجموعات لأول مرة.. والتشيك تودع المونديال]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
نبض اليوم الـ15 من مونديال 2026.. العد التنازلي للأدوار الإقصائية
![نبض اليوم الـ15 من مونديال 2026.. العد التنازلي للأدوار الإقصائية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
المغرب ينتفض أمام هايتي برباعية ويبلغ دور الـ32 في كأس العالم
![المغرب ينتفض أمام هايتي برباعية ويبلغ دور الـ32 في كأس العالم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![مونديال 2026]() مونديال 2026
مونديال 2026
-
![اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات]()
اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات
RT STORIES
مصدر لـRT: إيران تشك في "تقسيم العمل" الأمريكي وتؤكد تمسكها بحلفائها وبرنامجها الصاروخي
![مصدر لـRT: إيران تشك في "تقسيم العمل" الأمريكي وتؤكد تمسكها بحلفائها وبرنامجها الصاروخي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
فضل الله: إسرائيل ترتكب خروقات تمهيدا للتملص من "التفاهم الأمريكي - الإيراني" حول لبنان
![فضل الله: إسرائيل ترتكب خروقات تمهيدا للتملص من "التفاهم الأمريكي - الإيراني" حول لبنان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إيران تستثمر تصريحات روته وتوجه اتهامات لدولتين أوروبيتين بدعم الحرب ضدها
![إيران تستثمر تصريحات روته وتوجه اتهامات لدولتين أوروبيتين بدعم الحرب ضدها]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الحرس الثوري يحذر السفن من ممرات عبر هرمز تم الإعلان عنها "دون تنسيق مع إيران"
![الحرس الثوري يحذر السفن من ممرات عبر هرمز تم الإعلان عنها "دون تنسيق مع إيران"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مدرسة ميناب.. قد لا يتم التوصل أبدا إلى تحديد المسؤول عن استهدافها خلال الحرب على إيران
![مدرسة ميناب.. قد لا يتم التوصل أبدا إلى تحديد المسؤول عن استهدافها خلال الحرب على إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"حزب الله" يصدر بيانا بشأن استهداف إسرائيل لمواطنين لبنانيين: نراقب ونرصد الانتهاكات
!["حزب الله" يصدر بيانا بشأن استهداف إسرائيل لمواطنين لبنانيين: نراقب ونرصد الانتهاكات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إيطاليا توبخ أمين عام الناتو بسبب تصريحاته حول استخدام القواعد الأمريكية خلال الحرب مع إيران
![إيطاليا توبخ أمين عام الناتو بسبب تصريحاته حول استخدام القواعد الأمريكية خلال الحرب مع إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ترامب: إيران تقدم تنازلات كبيرة جدا في مفاوضاتها مع الولايات المتحدة
![ترامب: إيران تقدم تنازلات كبيرة جدا في مفاوضاتها مع الولايات المتحدة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات]() اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات
اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات
-
![زلزال فنزويلا]()
زلزال فنزويلا
RT STORIES
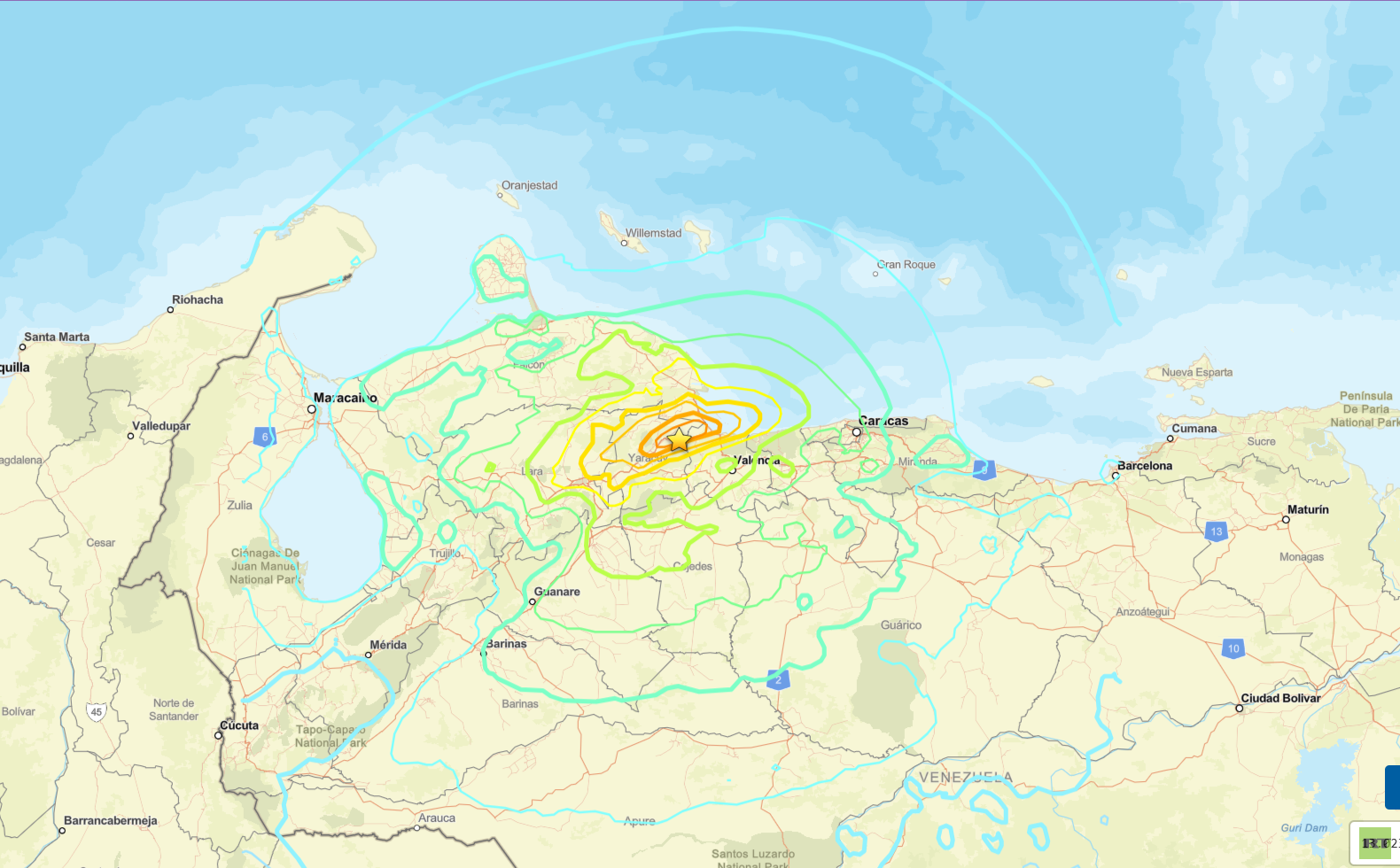
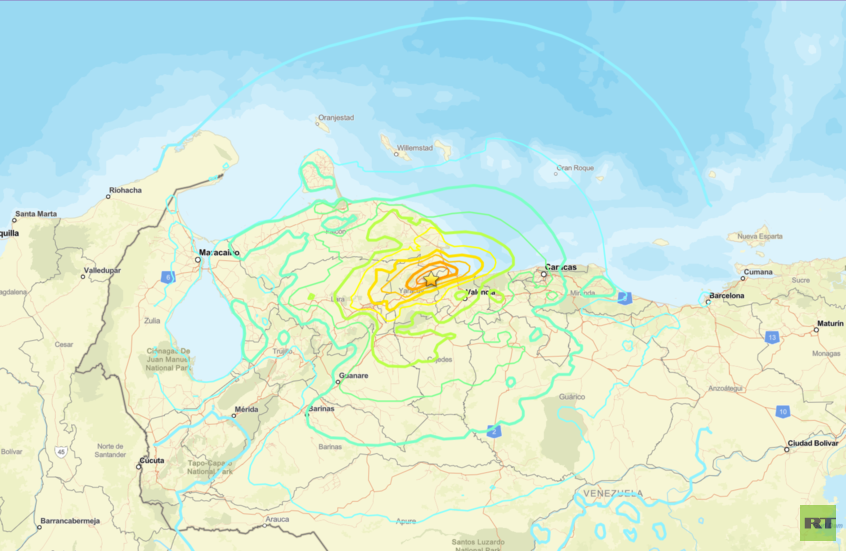
فنزويلا تعلن حالة الطوارئ.. عشرات القتلى والجرحى في حصيلة أولية للزلزالين المدمرين (فيديو)
![فنزويلا تعلن حالة الطوارئ.. عشرات القتلى والجرحى في حصيلة أولية للزلزالين المدمرين (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
زلزالان قويان يضربان فنزويلا.. دمار هائل ومخاوف من خسائر بشرية كبيرة (فيديو)
![زلزالان قويان يضربان فنزويلا.. دمار هائل ومخاوف من خسائر بشرية كبيرة (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مادورو من خلف القضاب الأمريكية: لا تتركوا أحداً بمفرده" في وجه زلزال فنزويلا المدمر!
![مادورو من خلف القضاب الأمريكية: لا تتركوا أحداً بمفرده" في وجه زلزال فنزويلا المدمر!]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الخارجية الأمريكية: الولايات المتحدة تستعد لتقديم مساعدات إلى فنزويلا بعد الزلزال
![الخارجية الأمريكية: الولايات المتحدة تستعد لتقديم مساعدات إلى فنزويلا بعد الزلزال]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![زلزال فنزويلا]() زلزال فنزويلا
زلزال فنزويلا
-
![بعد رفع العقوبات الرياضية.. اعتراض روماني على عودة الرموز الروسية في كأس العالم للجمباز]()
بعد رفع العقوبات الرياضية.. اعتراض روماني على عودة الرموز الروسية في كأس العالم للجمباز
RT STORIES
بعد رفع العقوبات الرياضية.. اعتراض روماني على عودة الرموز الروسية في كأس العالم للجمباز
![بعد رفع العقوبات الرياضية.. اعتراض روماني على عودة الرموز الروسية في كأس العالم للجمباز]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More



























DeepSeek تطلق ذكاء اصطناعيا جديدا يتفوق على معظم النماذج مفتوحة المصدر
أطلقت DeepSeek الصينية أحدث نماذجها في مجال الذكاء الاصطناعي، الإصدار الرابع (V4)، في خطوة جديدة تعكس تصاعد المنافسة العالمية في هذا القطاع.

وأوضحت الشركة أن النموذج الجديد يأتي بإصدارين هما DeepSeek-V4-Pro وDeepSeek-V4-Flash، مشيرة إلى أن الإصدار الثاني يتميز بكفاءة أعلى وتكلفة تشغيل أقل، بينما يقدم الإصدار الاحترافي قدرات أقوى في الاستدلال والمعرفة والتحليل.
وأكدت الشركة، التي تتخذ من مدينة هانغتشو مقرا لها، أن DeepSeek-V4-Pro يتمتع بسياق فائق الطول يصل إلى مليون رمز، ما يمنحه قدرة كبيرة على فهم النصوص الطويلة ومعالجة كميات ضخمة من البيانات، وهو ما وصفته بأنه إنجاز جديد في مجال النماذج مفتوحة المصدر.
وأضافت أن هذا الإصدار يحقق أداء متقدما في قدرات الوكيل الذكي والمعرفة العالمية والاستدلال، كما أنه يتفوق على معظم النماذج مفتوحة المصدر الأخرى، ولا يسبقه سوى نموذج Gemini-Pro-3.1 من غوغل، وهو نموذج مغلق المصدر.

"أنثروبيك" تفاجئ العالم بذكاء اصطناعي أقوى من أن يُطرح للعامة!
كما زُوّد DeepSeek-V4-Pro بما وصفته الشركة بـ"وضع بذل أقصى جهد في الاستدلال"، وهي ميزة تهدف إلى تحسين قدرات النموذج المعرفية بشكل أكبر، وترسيخ مكانته كأفضل نموذج مفتوح المصدر متاح حاليا.
وأشارت الشركة إلى أن النموذج الجديد جرى تحسينه ليتوافق بصورة أفضل مع المعالجات الصينية المحلية، في ظل القيود المتزايدة التي تفرضها الولايات المتحدة على صادرات أشباه الموصلات المتقدمة إلى الصين، خاصة وحدات معالجة الرسومات (GPUs) الضرورية لتطوير نماذج الذكاء الاصطناعي.
ورغم أن الشركة لم تكشف عن نوع الشرائح المستخدمة في تدريب نموذج V4، فإنها أوضحت أن مكوناته البرمجية مصممة للعمل مع شرائح شركتي Nvidia وHuawei.
وحتى الآن، أعلنت الشركة أن النموذج قادر على معالجة ما يصل إلى 384 ألف رمز، موضحة أن الرموز تمثل الوحدة الأساسية للبيانات التي تتعامل معها نماذج الذكاء الاصطناعي، وقد تكون كلمات أو أحرفا، وكلما زادت قدرة النموذج على معالجتها بسرعة، ارتفعت كفاءته في التعلم والاستجابة.
وأكدت DeepSeek أن الإصدار الجديد يحقق "قفزة نوعية في الكفاءة الحسابية" بفضل دعمه لسياق يصل إلى مليون رمز، ما يفتح الباب أمام جيل جديد من النماذج القادرة على التعامل مع نصوص وسيناريوهات أكثر تعقيدا وطولا.
وفي مقارنة مباشرة، قالت الشركة إن DeepSeek-V4-Pro يتفوق على Gemini-3.1-Pro من غوغل في فهم النصوص الطويلة، لكنه لا يزال أقل كفاءة من نموذج Claude Opus 4.6 التابع لشركة Anthropic.
ويأتي هذا الإطلاق بعد الضجة الكبيرة التي أثارتها الشركة العام الماضي عند طرح نموذجها R1، الذي نافس أداء أنظمة الذكاء الاصطناعي مثل ChatGPT رغم تطويره بتكلفة أقل بكثير، ما تسبب حينها في اضطرابات كبيرة بأسواق الأسهم.
وأكدت الشركة في ختام بيانها أنها تسعى من خلال هذا الإصدار إلى تعزيز ذكاء النموذج وقوته العملية، وتوسيع نطاق استخدامه في مختلف المهام والسيناريوهات اليومية والمهنية.
المصدر: إندبندنت
إقرأ المزيد

مشكلة "الثقة المفرطة" في الذكاء الاصطناعي تقترب من الحل
قد يكون الذكاء الاصطناعي، بما يملكه من مخزون هائل من المعرفة، مفيدا للغاية، إلا أن له عيبا واحدا قد يحدّ من مزاياه، وهو الثقة المفرطة في الإجابة.

البنتاغون سيستخدم نماذج الذكاء الاصطناعي من OpenAI في شبكته المغلقة
أعلن رئيس شركة OpenAI سام ألتمان أن الشركة توصلت إلى اتفاق مع البنتاغون لاستخدام نماذج الذكاء الاصطناعي الخاصة بها في الشبكة المغلقة التابعة للبنتاغون.

DeepSeek تعلن عن نموذجها التجريبي الجديد للذكاء الاصطناعي
أعلنت شركة DeepSeek الصينية عن إصدار تجريبي جديد لنموذج مساعدها الذكي الذي يعمل بالذكاء الاصطناعي.

DeepSeek تحذر المستخدمين من انتشار معلومات كاذبة عنها
حذّرت شركة DeepSeek الصينية مستخدمي الإنترنت من انتشار معلومات كاذبة عنها، وأوصت باستخدام مواقعها الرسمية.
































































































التعليقات